pypdfでPDFを分割・結合・テキスト抽出・画像抽出する
仕事でよく使う資料ってPDFファイルが多いと思います。
PDFのファイルを仕事で使用する際に、複数ページを1枚ずつに分割したり、複数のPDFを1つにまとめたり、テキストや画像を抽出したりと、いろんな作業をすることがあると思います。
多くの場合、Adobe AcrobatなどのPDFソフトを使って、これら作業を行っていると思いますが、マウス操作だと時間がかかって効率が悪いと思う方がいらっしゃると思います。
そこで今回は、Pythonライブラリのpypdfを使って、これらの作業を時間を掛けないで行う方法をご紹介します。
pypdfを使えば、VS Code上でコードを入力するだけで、簡単にPDFの分割や結合、テキスト抽出、画像の抽出を行うことが出来ます。
マウス操作よりも圧倒的に早く作業を終わらせることができますので、作業時間の短縮に繋がります。
今回のブログ記事では、そのpypdfでPDFの分割や結合、テキスト抽出、画像の抽出の方法をご紹介します。


pypdfを使用する際の準備
Pythonのインストール
pypdfを使用するためには、まずPythonをパソコンにインストールする必要があります。以下は、Windows、Mac、およびChromebookのLinux開発環境へのPythonのインストール手順を紹介します。
WindowsにPythonをインストール
Windows環境にPythonをインストールするには、Pythonプログラミング VTuber サプー様の分かりやすい動画がありますので参考にしてください。
MacにPythonをインストール
Mac環境にPythonをインストールするには、Pythonプログラミング VTuber サプー様の分かりやすい動画がありますので参考にしてください。
LinuxにPythonをインストール
LinuxにPythonをインストールするには、以下のジコログ様のブログ記事を参考に行ってください。

ChromebookのLinux開発環境にPythonをインストール
ChromebookのLinux開発環境にPythonをインストールするには、以下のテックキャンプ ブログ様のブログ記事を参考に行ってください。

pypdfのインストール
pypdfを使用する場合、pypdfをインストールします。
Windows、Mac、Linuxの場合
OpenPyXLをインストールする手順は簡単です。Windowsの場合はコマンドプロンプト、MacやLinuxの場合はターミナルや端末を開いて、以下のコマンドを入力してください。
pip install pypdfもしpypdfが正しくインストールできない場合、それはpipライブラリが十分にインストールされていない可能性があります。pipはPythonのパッケージ管理を担うライブラリであり、正しく動作することが必要です。
次に、以下のコマンドを実行してpipライブラリを最新バージョンにアップデートし、その後に再度pypdfをインストールしてみてください。
以下のコードを実行したのちに、pypdfを再インストールを実行してみてください。
python -m pip install --upgrade pip
python -m pip install pypdfこうすることで、pipライブラリが最新の状態に更新され、pypdfの再インストールが出来ます。
Chromebookの場合
ChromebookのLinux開発環境の場合は、WindowsやMac、Linuxとはインストール方法が異なります。
以下のサイトを参考にインストールを行ってください。
VS Codeのインストール
VSCodeはMicrosoftが無料で提供している言語のいろんなプログラミングのコードを書くために用いられるコードエディターでPythonのコードを書くことが出来ます。
Windows、Mac、Linux、ChromebookのLinux開発環境にインストール出来ます。
VSCodeをインストールするには、Pythonプログラミング VTuber サプー様の分かりやすい動画があり、Pythonのコードを書くための拡張機能のインストール方法も解説されているので、参考にしてください。
【pypdfの使い方】pypdfでPDFを分割・結合・テキスト抽出・画像抽出する方法
pypdfでPDFの分割や結合、テキスト抽出の方法を順次解説していきます。
その前にPythonのファイルを作り、任意の場所に保存してください。
ファイル名ですが、お好きなファイル名にしてください(私はpypdf.pyにしました)。
※この記事では以下のChromebookのLinux開発環境で行いましたが、Windows、Mac、Linuxでも同じ作業でpypdfで、PDFの分割や結合、テキスト抽出が出来ます。
なお今回のブログ記事ですが、私が作成したPDFファイルであるUbuntu Presentation.pdf、Chromebook-Presentation.pdfの2つを使用して説明します。
なおこのブログ記事では、Pythonがよく分からないという方のために、詳しい説明をしないで、基本的なコードを載せて、それを使って例として実際に作業した結果を載せます。
pyapdfでPDFの分割する方法
ファイルを分割する基本コードは以下の通りです。
reader = PdfReader("分割したいファイル名.pdf")
for page_num in range(len(reader.pages)):
writer = PdfWriter()
page = reader.pages[page_num]
writer.add_page(page)
output_filename = f"分割したいファイル名_{page_num + 1}.pdf"
with open(output_filename, "wb") as output_file:
writer.write(output_file)
print(f"分割したいファイル名 {page_num + 1} saved as {output_filename}")分割したいファイル名は、実際に分割を行うPDFファイルのファイル名です。
このコードをVS Codeに入力することで、分割したいファイル名の後に、_ページ数が付きます。
では計3ページあるUbuntu Presentation.pdfを使って、PDFファイルを3ファイルに分割してみます。
以下のようなコードを入力します。
from pypdf import PdfReader, PdfWriter
reader = PdfReader("Ubuntu Presentation.pdf")
for page_num in range(len(reader.pages)):
writer = PdfWriter()
page = reader.pages[page_num]
writer.add_page(page)
output_filename = f"Ubuntu Presentation_{page_num + 1}.pdf"
with open(output_filename, "wb") as output_file:
writer.write(output_file)
print(f"Ubuntu Presentation {page_num + 1} saved as {output_filename}")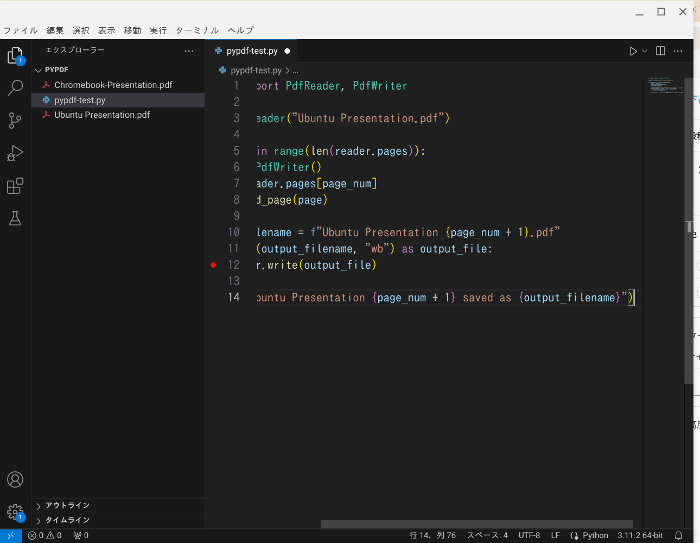
左上の実行ボタンをクリックします。
するとUbuntu Presentation_1.pdf、Ubuntu Presentation_2.pdf、Ubuntu Presentation_3.pdfと3つのファイルに分割されます。
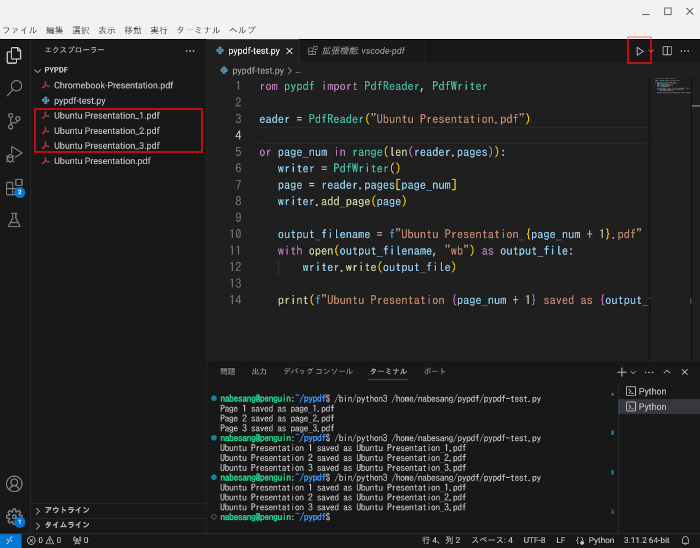
これを1ページずつ確認したい場合は、VS Codeの拡張機能であるvscode-pdfをインストールすると便利です。
これをインストールすると、右側にファイル名が表示されているPDFファイルをクリックすると、VS CodeでPDFファイルを表示させることが出来ます。
以下が分割したPDFファイルです。
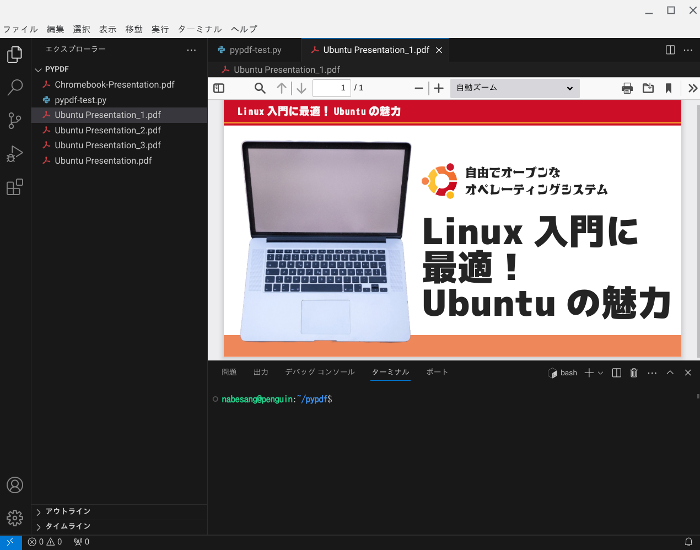
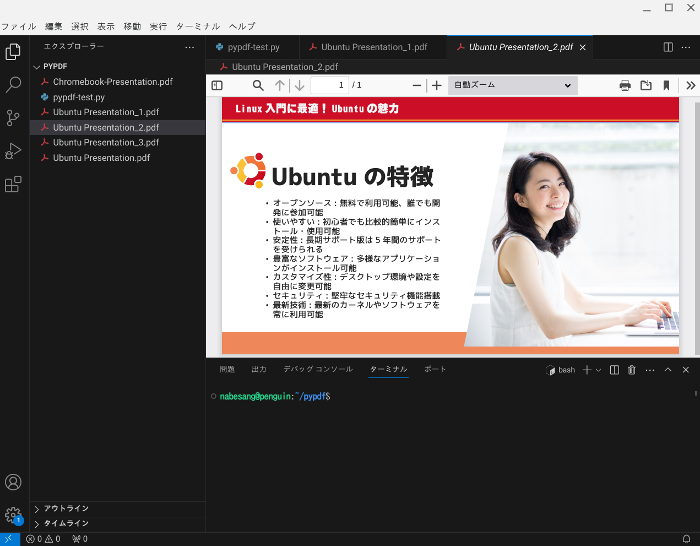
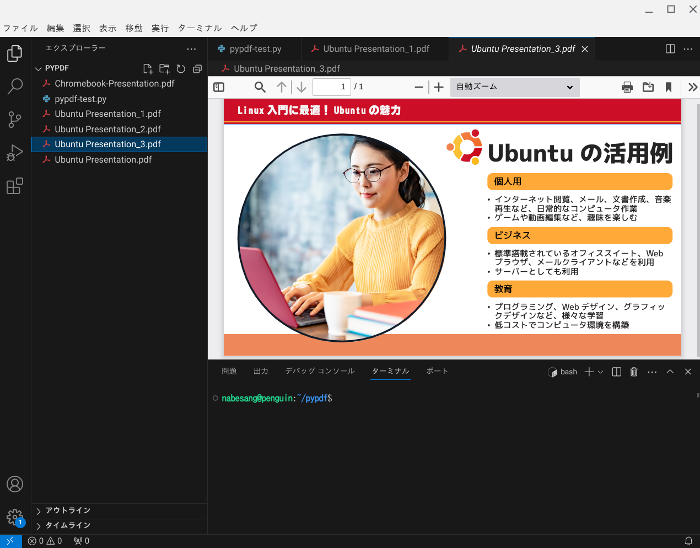
pyapdfでPDFの結合する方法
PDFの結合の基本コードは以下の通りです。
from pypdf import PdfReader, PdfWriter
reader1 = PdfReader("結合したいファイル1.pdf")
reader2 = PdfReader("結合したいファイル2.pdf")
writer = PdfWriter()
for page in reader1.pages:
writer.add_page(page)
for page in reader2.pages:
writer.add_page(page)
with open("結合したファイル.pdf", "wb") as output_file:
writer.write(output_file)結合したいファイル1、結合したいファイル2は、結合をしたいファイルのことです。
結合したファイルは、結合したいファイル1、結合したいファイル2を結合したファイルのことです。
このコードをVS Codeに入力することで、2つのPDFファイルが結合され1つのPDFファイルとなります。
今回は例として、Ubuntu Presentation.pdfとChromebook-Presentation.pdfを結合してみます。
今回は、結合したファイルの名前は、Ubuntu Presentation+Chromebook-Presentation.pdfにします。
以下のようなコードを入力します。
from pypdf import PdfReader, PdfWriter
reader1 = PdfReader("Ubuntu Presentation.pdf")
reader2 = PdfReader("Chromebook-Presentation.pdf")
writer = PdfWriter()
for page in reader1.pages:
writer.add_page(page)
for page in reader2.pages:
writer.add_page(page)
with open("Ubuntu Presentation+Chromebook-Presentation.pdf", "wb") as output_file:
writer.write(output_file)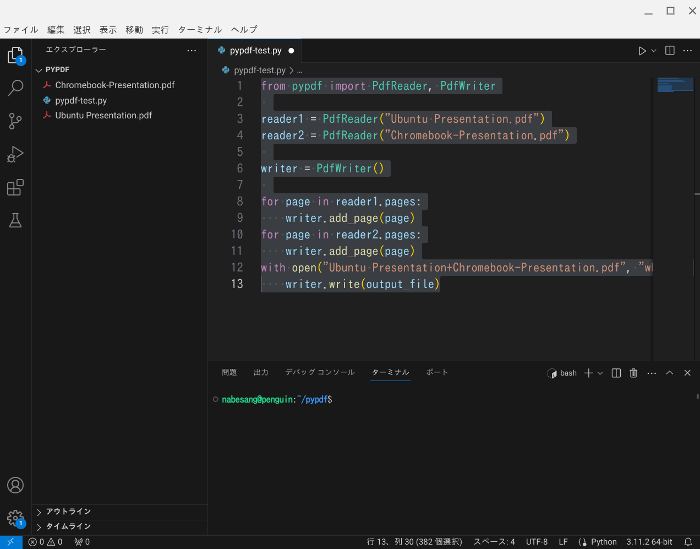
左上の実行ボタンをクリックします。
すると、Ubuntu Presentation.pdfとChromebook-Presentation.pdfが結合したPresentation+Chromebook-Presentation.pdfが作成されます。
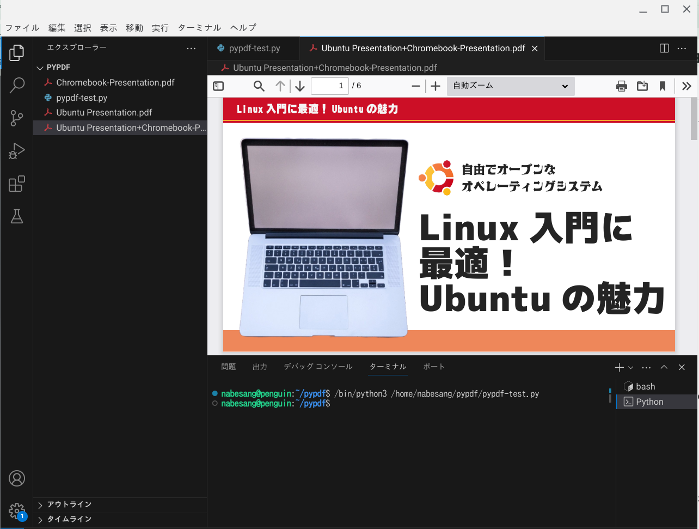
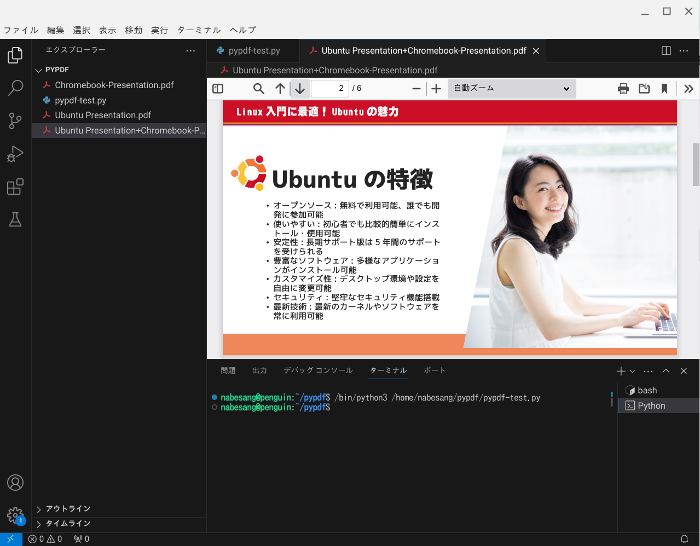
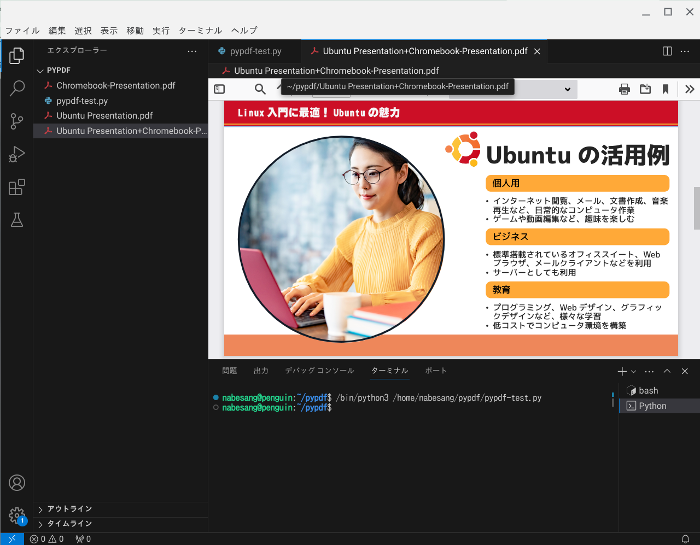
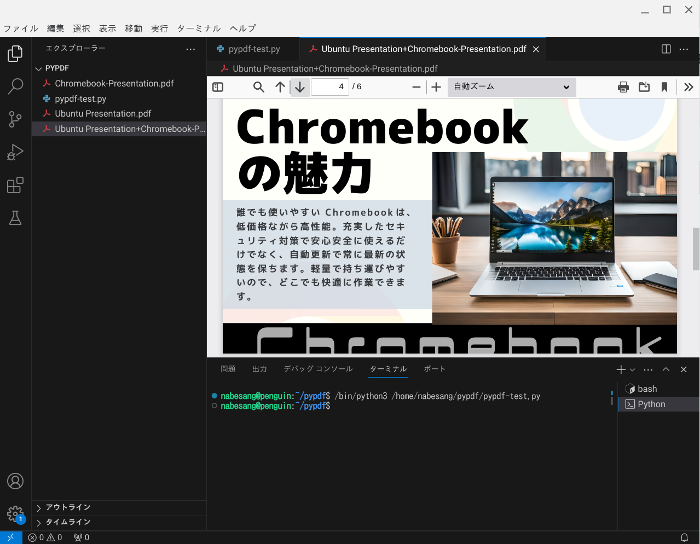
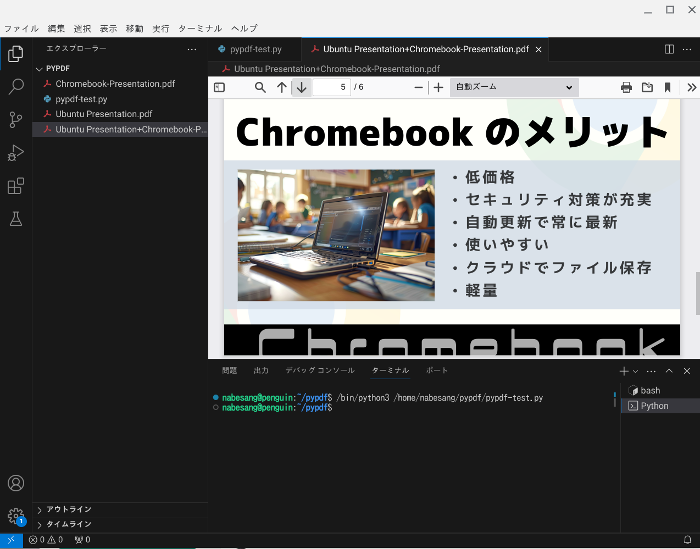
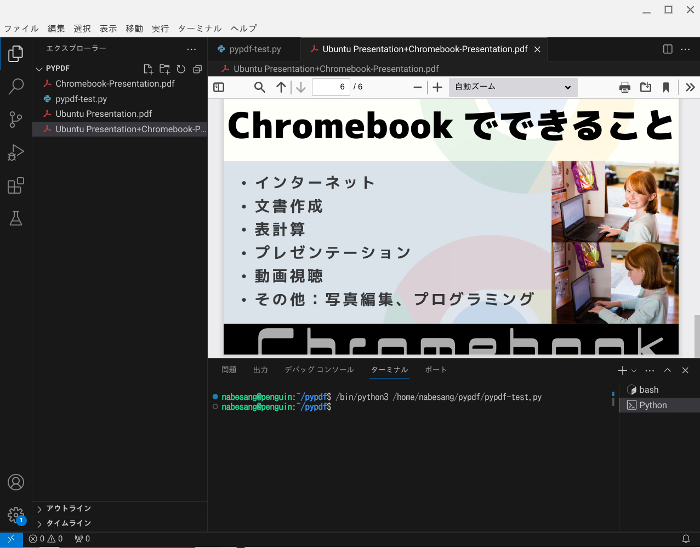
なお多くのPDFを結合する場合は、以下のようにコードを入力します。
reader1 = PdfReader("結合したいファイル1.pdf")
reader2 = PdfReader("結合したいファイル2.pdf")
reader3 = PdfReader("結合したいファイル3.pdf")
reader4 = PdfReader("結合したいファイル4.pdf")
reader5 = PdfReader("結合したいファイル5.pdf")
reader6 = PdfReader("結合したいファイル6.pdf")
︙
︙
︙pyapdfでPDFにパスワードをつける方法
pypdfでは、PDFを保護するためにパスワードを設定することが出来ます。
PDFにパスワードを設定する基本コードは以下の通りです。
from pypdf import PdfReader, PdfWriter
reader = PdfReader("パスワードを設定したいファイル.pdf")
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
writer.encrypt("password")
with open("パスワードを設定した.pdf", "wb") as output_file:
writer.write(output_file)パスワードを設定したいファイルは、パスワードを設定する元のファイルです。
パスワードを設定した.pdfは、実際にパスワードを設定したファイルです。
実際に、passwordは、実際に使うパスワードです。
では、例として、Chromebook-Presentation.pdfに、123456というパスワードを設定した、Chromebook-Presentation-password.pdfという作成してみます。
以下のようなコードを入力します。
from pypdf import PdfReader, PdfWriter
reader = PdfReader("Chromebook-Presentation.pdf")
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
writer.encrypt("123456")
with open("Chromebook-Presentation-password.pdf", "wb") as output_file:
writer.write(output_file)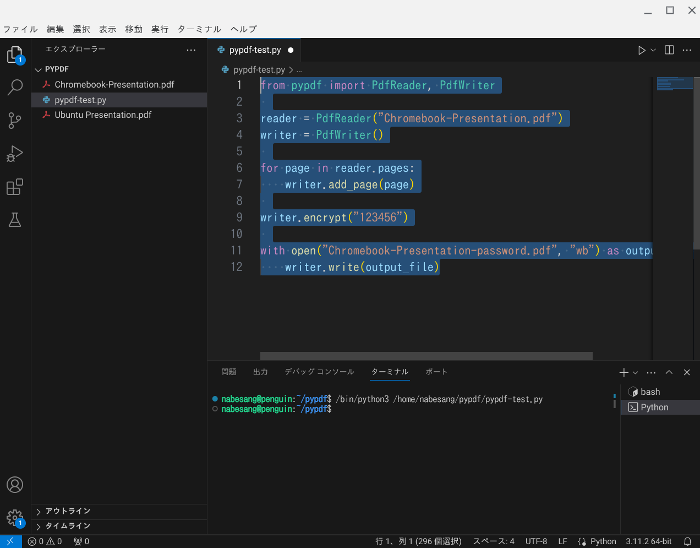
左上の実行ボタンをクリックします。
Chromebook-Presentation-password.pdfが作成されます。
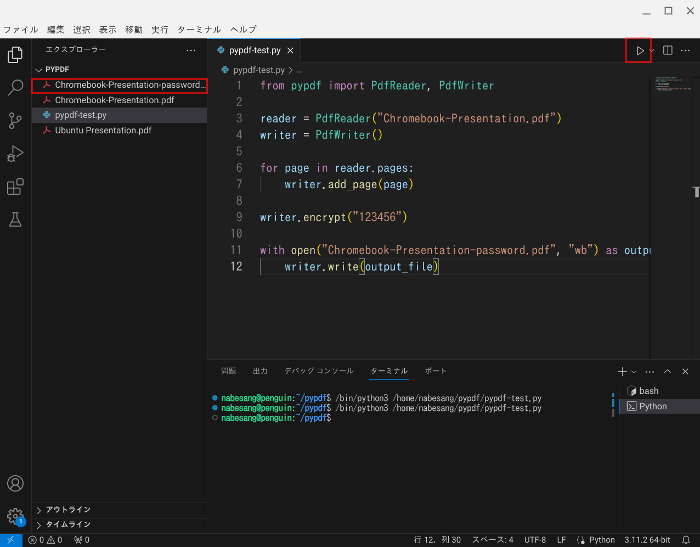
このChromebook-Presentation-password.pdfを開くと、パスワードを聞かれます。
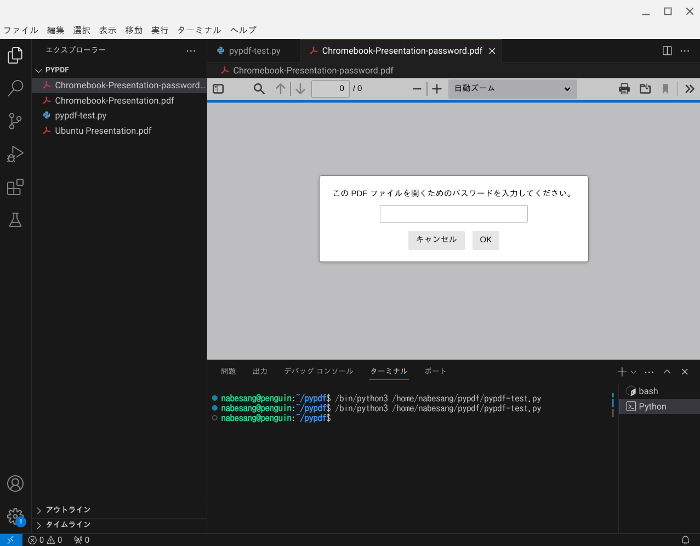
パスワードを入力し、OKをクリックします。
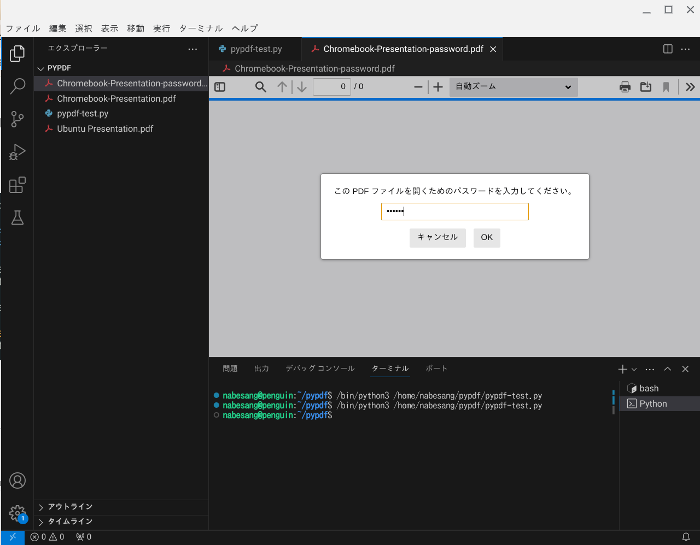
するとPDFが開きます。
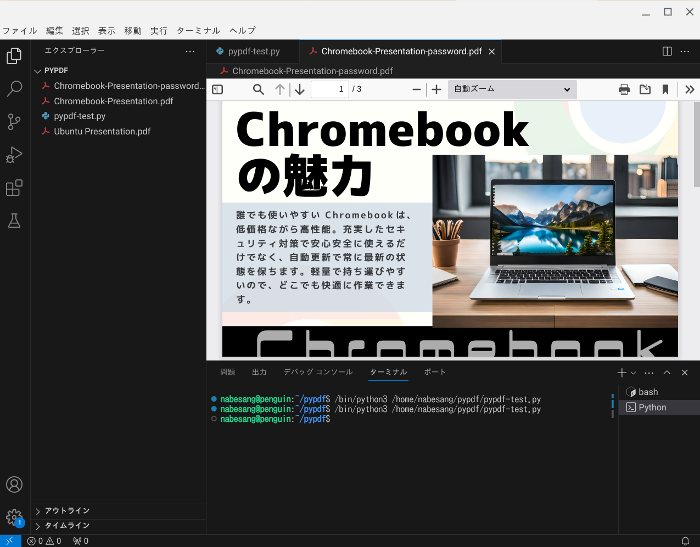
pyapdfでPDFのテキストを抽出する方法
PDFファイルに書かれたテキストだけをテキストエディタに貼り付けたい方はいらっしゃると思います。
その場合、マウス操作で選択して、コピーしてテキストエディタなどに貼り付けるということをされる方がいらっしゃると思います。
しかしこういう作業は時間がかかるものです。
pypdfなら、こんなことをしないで時間を掛けないでテキストを抽出することが出来ます。
今回はVS COdeを使用しているので、そのアプリケーションのターミナルにテキストが抽出されます。
後は、ターミナルに抽出されたテキストをコピーして、それをテキストエディタに貼り付けるだけなので、作業は圧倒的に早く済みます。
PDFのテキストを抽出する基本コードは以下の通りです。
from pypdf import PdfReader
reader = PdfReader("テキストを抽出したいファイル.pdf")
number_of_pages = len(reader.pages)
page = reader.pages[0]
text = page.extract_text()
print(text)
テキストを抽出したいファイルは、テキストを抽出するファイルのことです。
page = reader.page = reader.pages[0]は、テキストを抽出したいページを設定するものです。
page = reader.pages[0]の[0]の部分にテキストを抽出したいページの数字を入力します。
ここで注意してほしいのは、Pythonの番号のスタートは0からスタートするという点です。
例えば1ページの場合でしたら、1ではなく0と入力します。
では、例として、Ubuntu Presentation.pdfの3ページのテキストを抽出してみようと思います。
以下のようなコードを入力します。
from pypdf import PdfReader
reader = PdfReader("Ubuntu Presentation.pdf")
number_of_pages = len(reader.pages)
page = reader.pages[2]
text = page.extract_text()
print(text)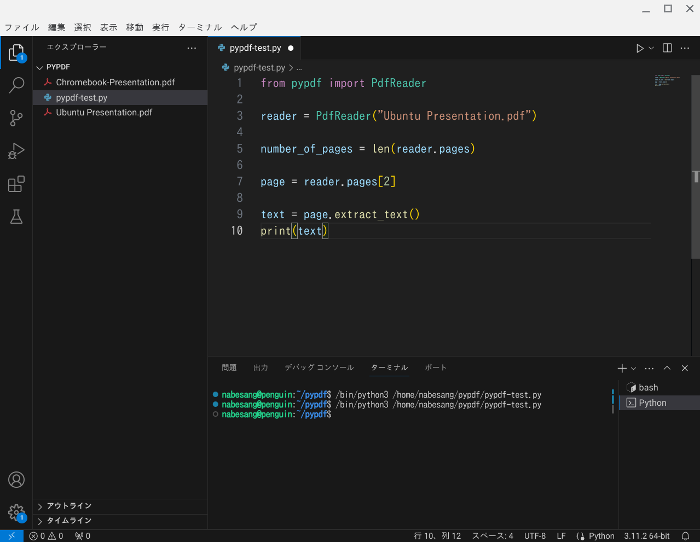
左上の実行ボタンをクリックします。
するとVS Codeのターミナルにテキストが抽出されます。
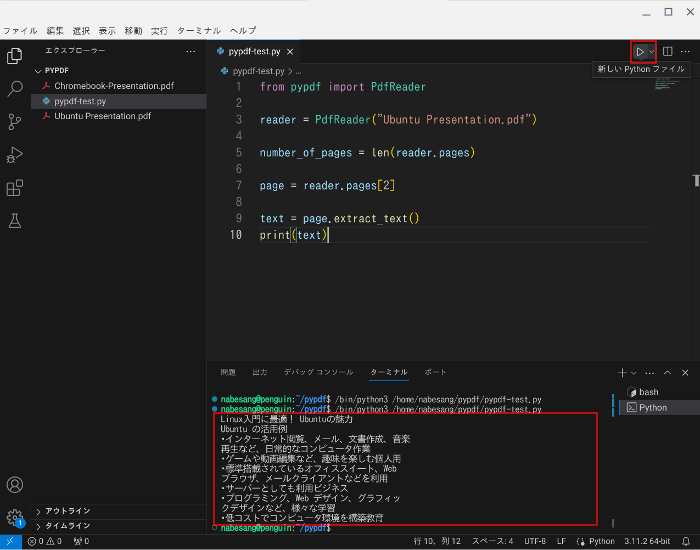
あとは、これをコピーして、テキストエディタに貼り付けるだけです。
pyapdfでPDFの画像を抽出する方法
PDFの画像を抽出したい方もいらっしゃると思います。
これを例えばAdobe Acrobatで行う場合、ツール/PDF を書き出しを選択して、「画像」を選択し、書き出すファイル形式および「すべての画像を書き出し」にチェックを入れて「書き出し」ボタンをクリックします。
この方法は、マウス操作で行うため、簡単といえば簡単ですが、方法をわざわざ覚えて行うため、面倒といえば面倒です。
しかし、pypdfを使えば、コードを入力するだけで、瞬間に画像を抽出できます。
PDFの画像を抽出する基本コードは以下の通りです。
from pypdf import PdfReader
reader = PdfReader("画像を抽出したいファイル.pdf")
page = reader.pages
page_num = len(page)
count = 0
for i in range(page_num):
page = reader.pages[i]
for image_file_object in page.images:
with open(str(count) + image_file_object.name, "wb") as fp:
fp.write(image_file_object.data)
count += 1画像を抽出したいファイルとは、抽出したい画像が入っているPDFファイルです。
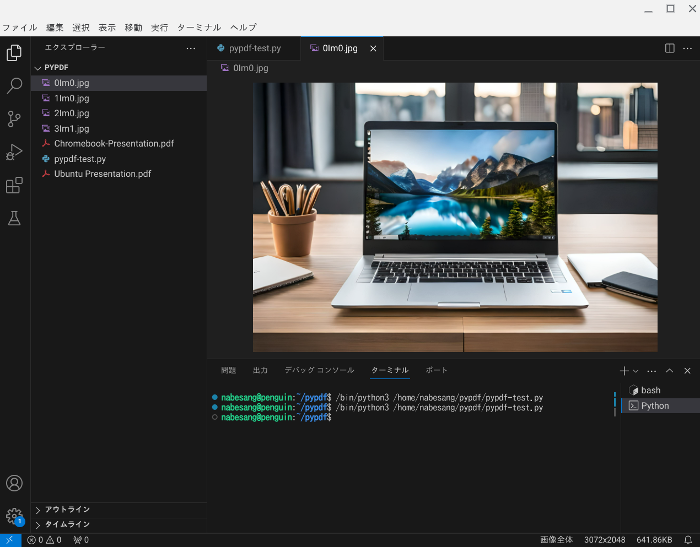
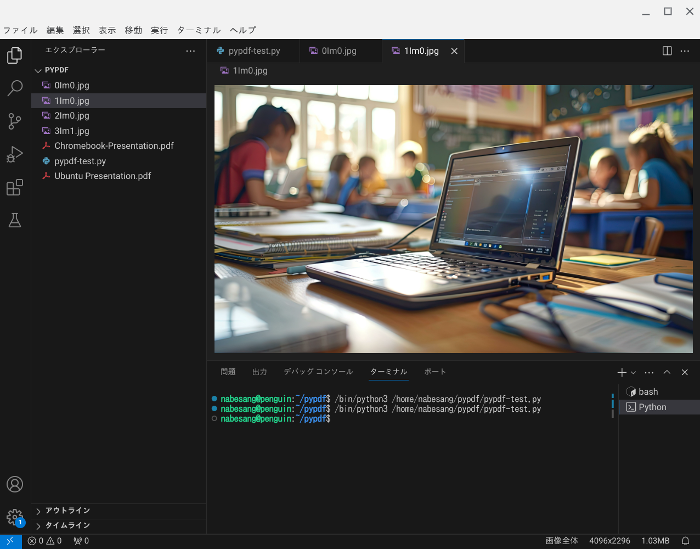
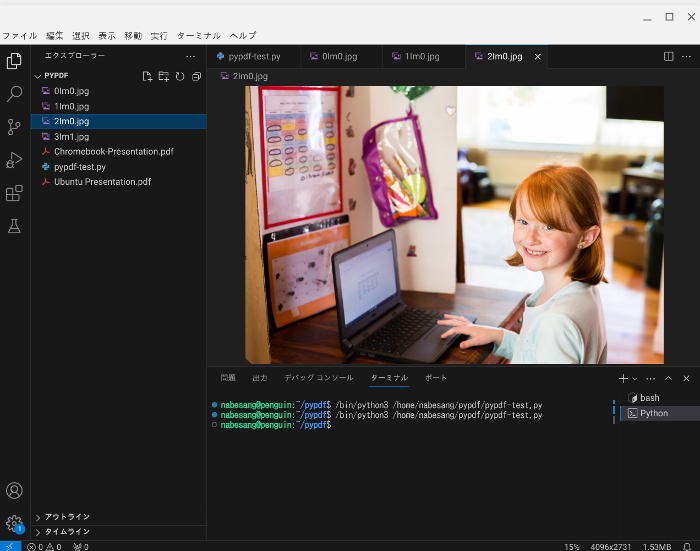
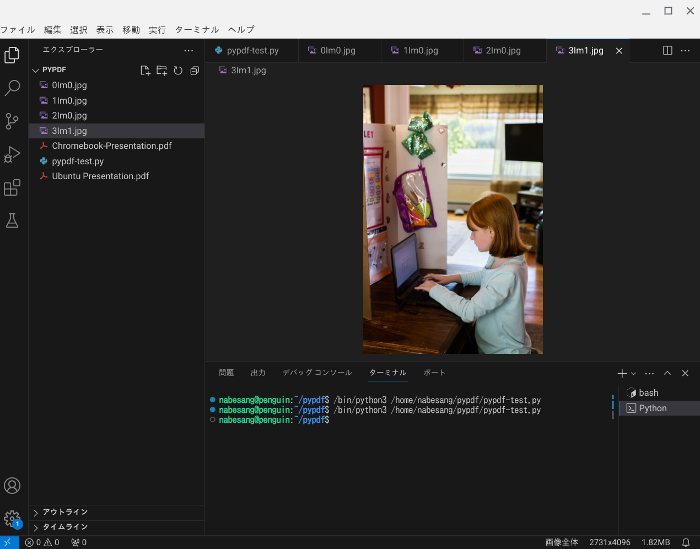
では、例として、Chromebook-Presentation.pdfの画像を抽出します。
以下のようなコードを入力します。
from pypdf import PdfReader
reader = PdfReader("Chromebook-Presentation.pdf")
page = reader.pages
page_num = len(page)
count = 0
for i in range(page_num):
page = reader.pages[i]
for image_file_object in page.images:
with open(str(count) + image_file_object.name, "wb") as fp:
fp.write(image_file_object.data)
count += 1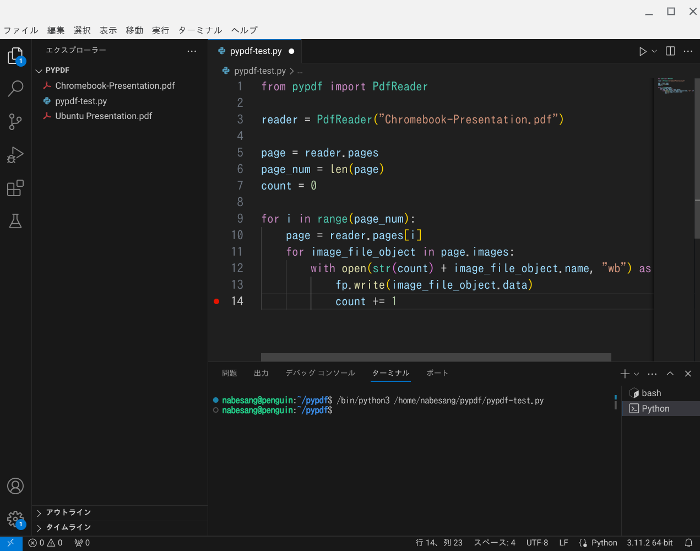
左上の実行ボタンをクリックします。
すると画像を抽出されます。
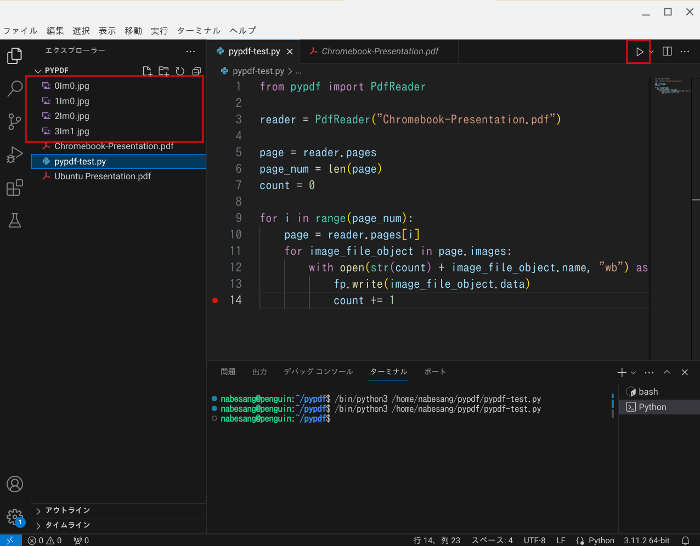
以下が、実際にPDFファイルから抽出された画像です。