

画像生成を快適に!Stable Diffusion WebUI Forgeの拡張機能
Stable Diffusion WebUI Forgeで画像を生成する際、プロンプトの入力や画像スタイルのプロンプトを調べたりすることが、手間がかかるため、面倒だと思う人は多いと思います。
そんな時に便利な拡張機能があります。
今回のブログ記事では、画像生成をより快適にするためのおすすめ拡張機能を3つご紹介します。
これらの拡張機能を活用することで、プロンプト作成の手間を大幅に軽減出来ると思います。
なお私は以下のパソコンの一世代前のモデルでStable Diffusion WebUI Forgeをインストールし、使用しています。拡張機能を追加しても快適に画像生成が出来ています。


画像生成を快適に!Stable Diffusion WebUI Forgeの拡張機能3選
1.prompt-all-in-one
Stable Diffusion WebUI Forgeで画像生成する際に、面倒なのはプロンプトを作ることでしょう。画像生成の専門的なプロンプトを調べたり、また具体的なプロンプトを日本語で描いた後に、Google翻訳して英語にするなど、これらはかなり面倒です。
それらを簡単にしてくれる拡張機能が、prompt-all-in-oneです。
prompt-all-in-oneのインストール及び設定の方法をご紹介します。
①Extensionsタブを選択し、Install From URLを選択する
Extensionsタブを選択します。
その中にInstall From URLという項目があるので、それを選択します。
②prompt-all-in-oneのURLアドレスを入力し、インストールをする
URL for extension’s git repositoryの入力欄に、以下のURLアドレスを入力します。
https://github.com/Physton/sd-webui-prompt-all-in-one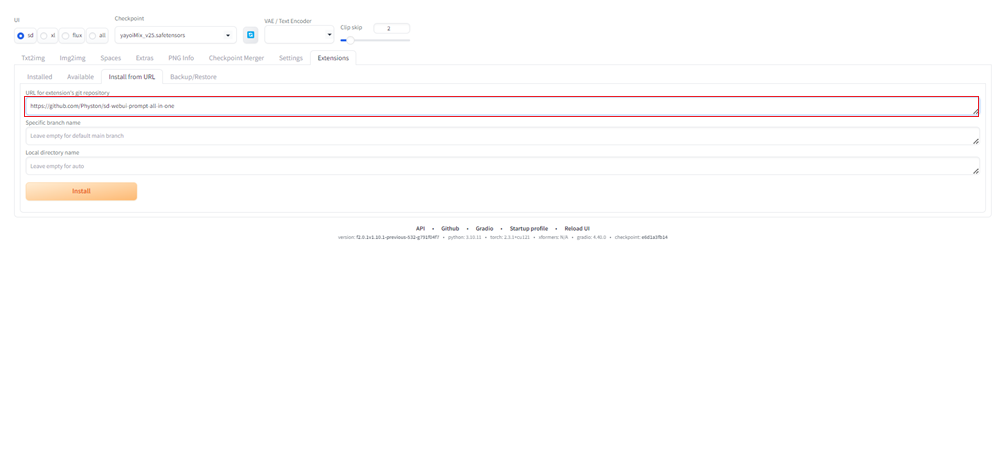
そのあとにInstallボタンをクリックします。
なおこの機能はインストールが完了するまで時間がかかりますが、気長に待ちましょう。
以下の画面のようにInstallボタンの下に文章が現れたらインストール完了です。
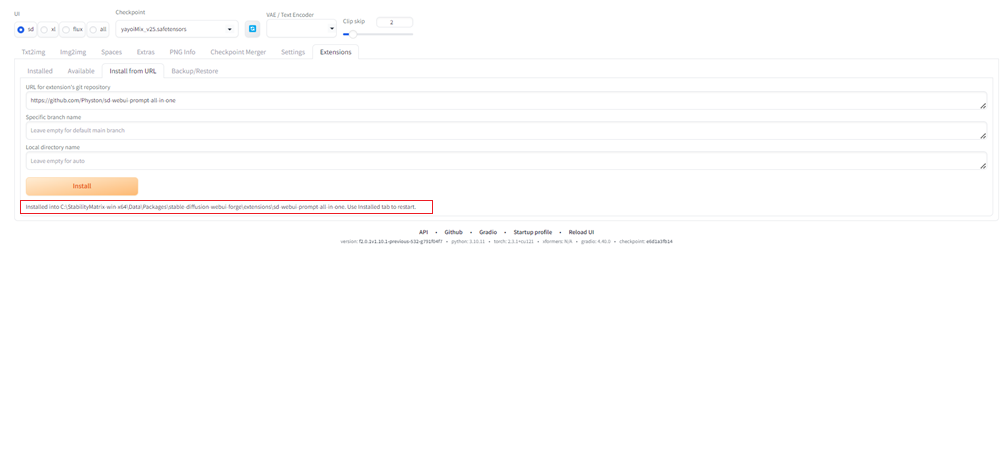
③実際にprompt-all-in-oneがインストールされたかを確認し、再起動する
実際にprompt-all-in-oneがインストールされたかを確認します。
Installedをクリックし、Check for updatesボタンをクリックします。
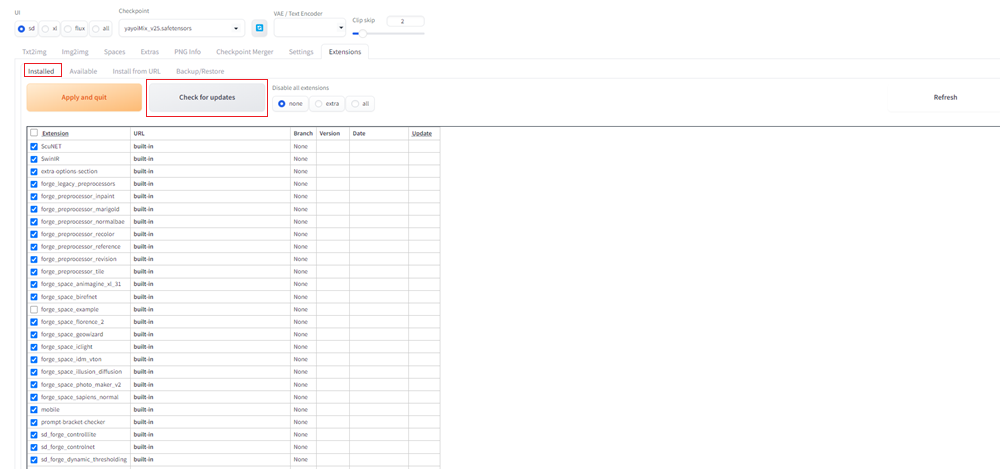
下へスクロールし、以下のような画面になっていたら、実際にprompt-all-in-oneことが確認できます。
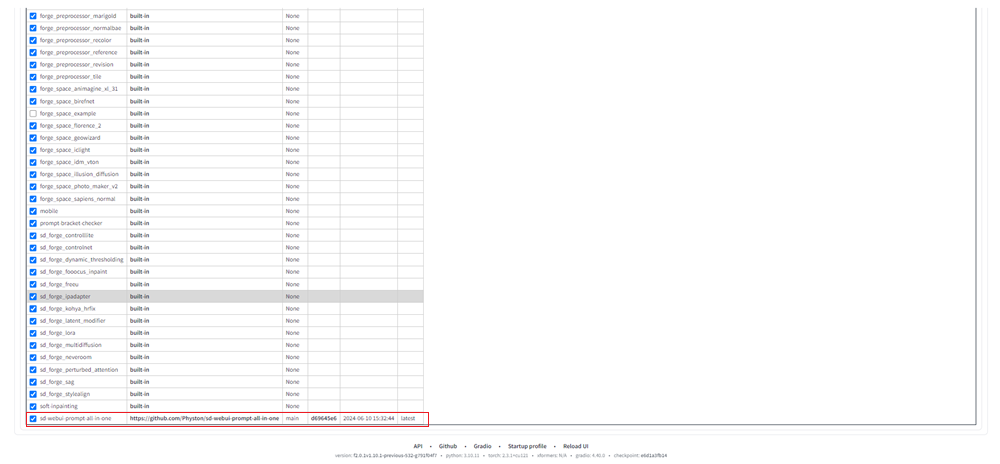
そうしたらAppy and quitボタンをクリックします。
すると、Stable Diffusion WebUI Forgeが再起動します。
なおなかなか再起動しない場合は、手動でStable Diffusion WebUI Forgeを終了させて再起動させてください。
④prompt-all-in-oneの設定
prompt-all-in-oneをインストールすると、このような画面になります。
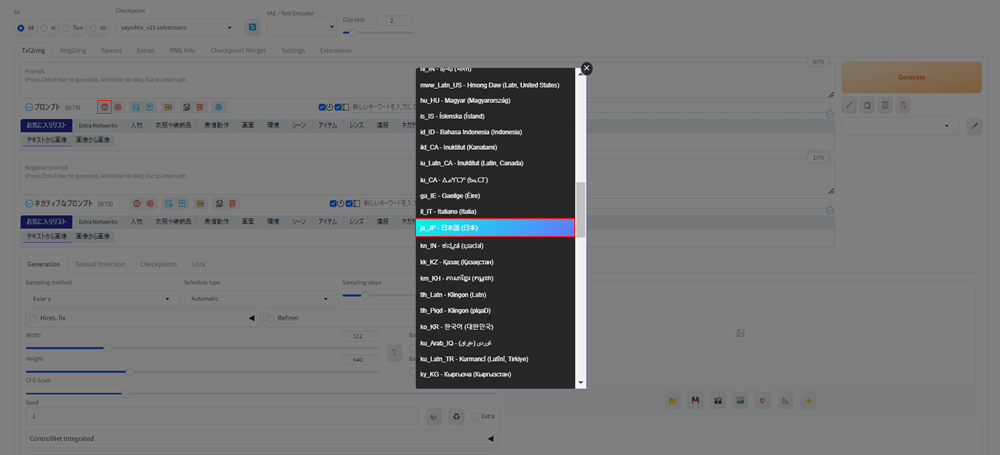
おそらく最初から日本語になっていると思いますが、なっていない場合はLanguageのアイコンをクリックし、日本語を設定してください。
これから自動翻訳の設定を行います。
設定:翻訳API、自動翻訳、表示/表示のアイコンをクリックします。
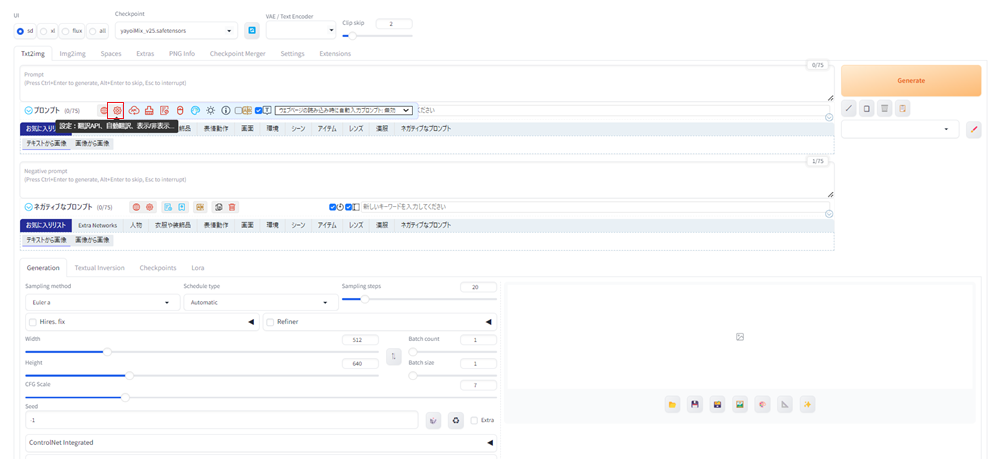
その横にある雲のアイコンをクリックします。
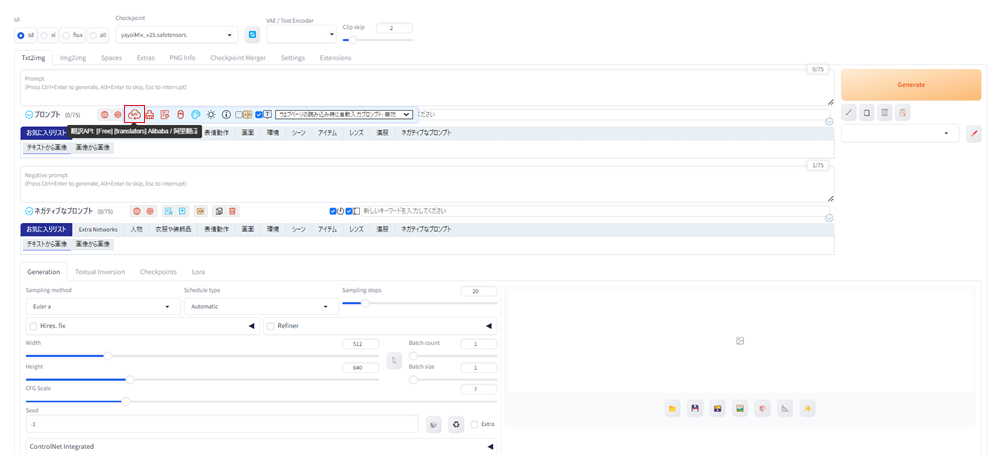
翻訳APIから[無料]Googleを選択します。
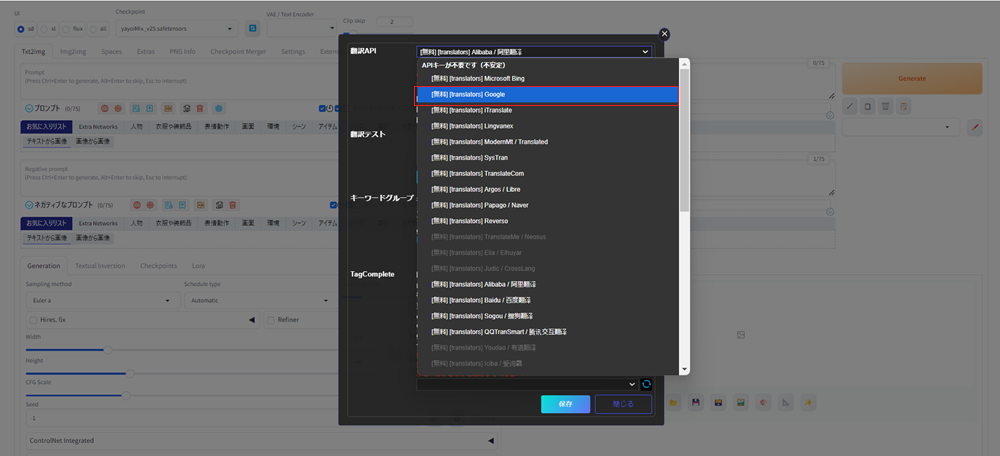
下へスクロールし、保存ボタンをクリックします。
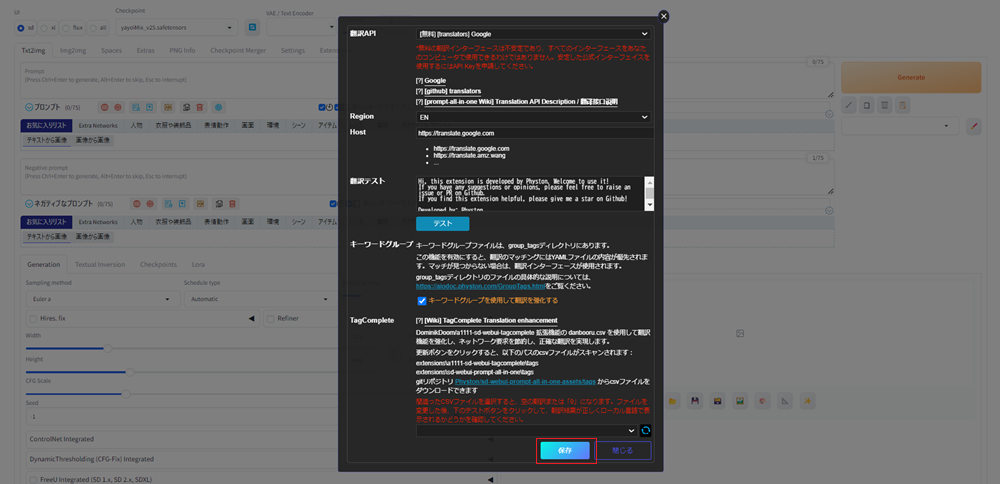
すると、「新しいキーワードを入力してください」という入力欄が現れます。
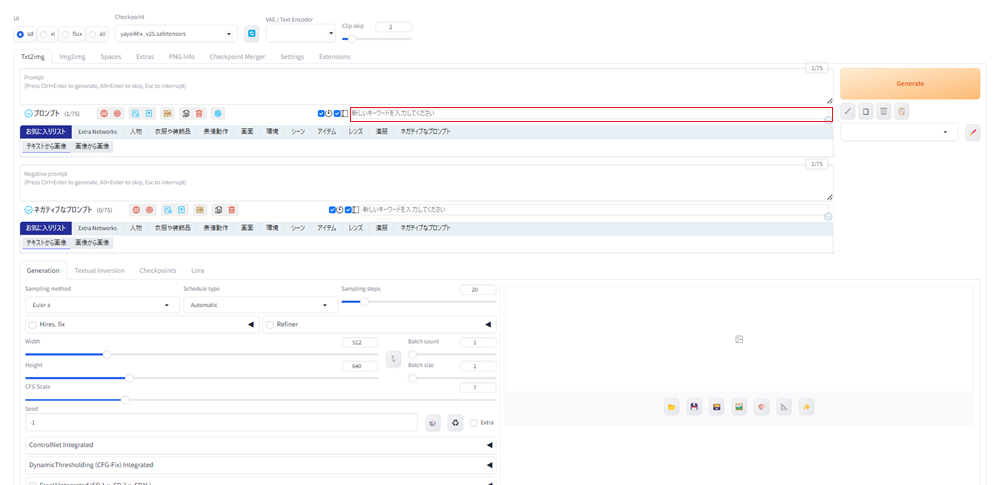
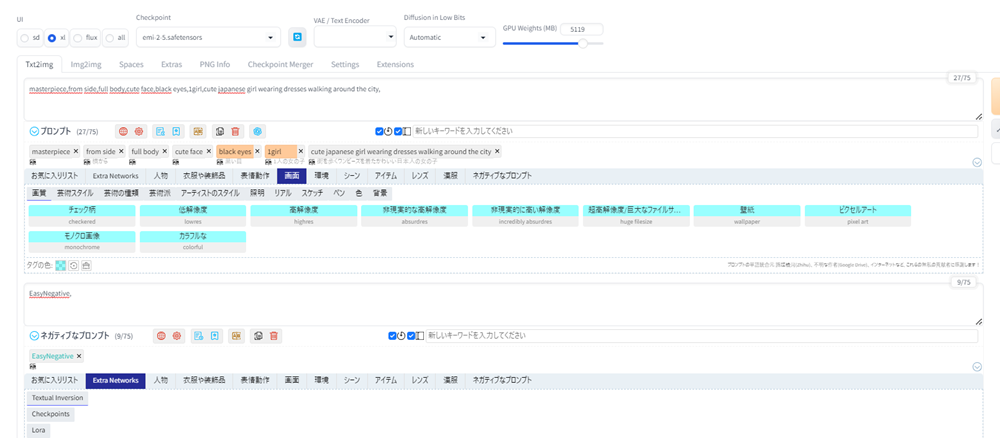
この入力欄に、日本語で入力しENTERキーを押すと、英語に翻訳してプロンプト欄に入力してくれます。
以下は、「街を歩くブラウスを着たかわいいアニメ風の日本人の女の子」と入力した結果の例です。
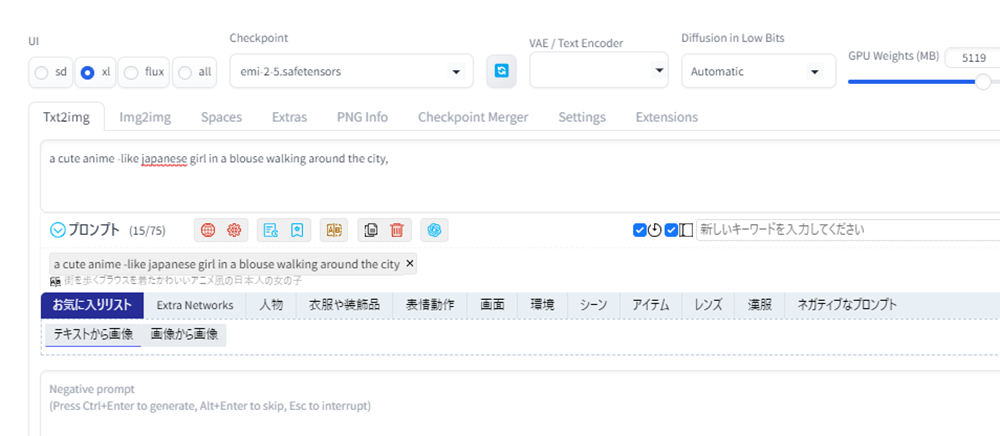
翻訳されたプロンプトを、Emi 2.5 Model Cardをモデルにして画像生成して見ましょう。
クオリティの高い画像を生成するために、以下の基本となるプロンプトを、prompt-all-in-oneで作ったプロンプトの前に入力しします。
masterpiece, from side, full body, cute face, black eyes,1girl,そして以下のネガティブプロンプトを入力します。
(worst quality,low quality:2),(painting,sketch,flat color),monochrome,grayscale,ugly face,bad face,bad anatomy,deformed eyes,missing fingers,acnes,skin blemishes,nsfw,nude,nipples、そしてGenerateボタンを押します。
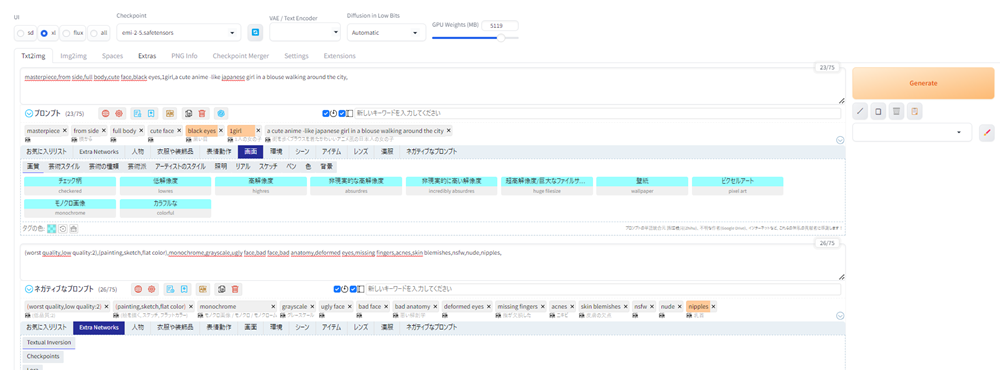
以下が生成した画像です。

prompt-all-in-oneは、Extra Networkの横の欄に多くのタブが並んでいて、それをクリックするとある程度のプロンプトの候補が現れます。
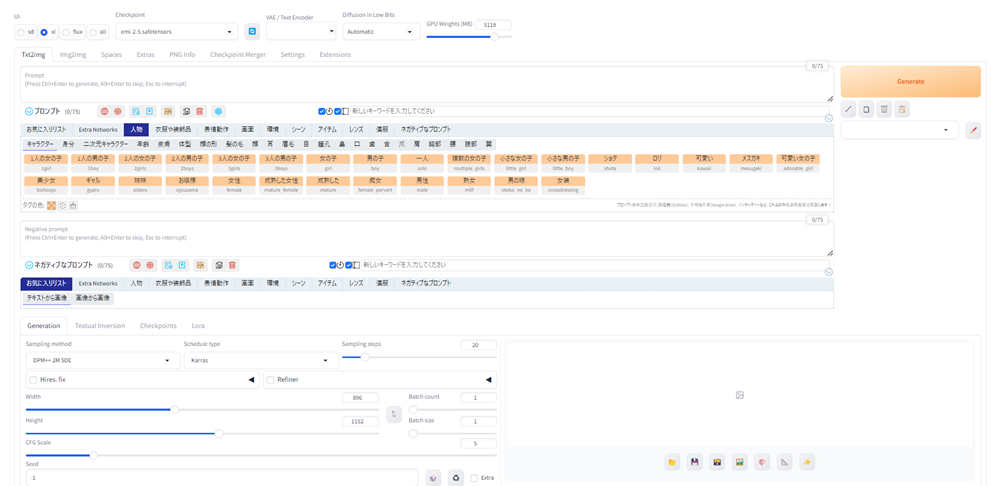
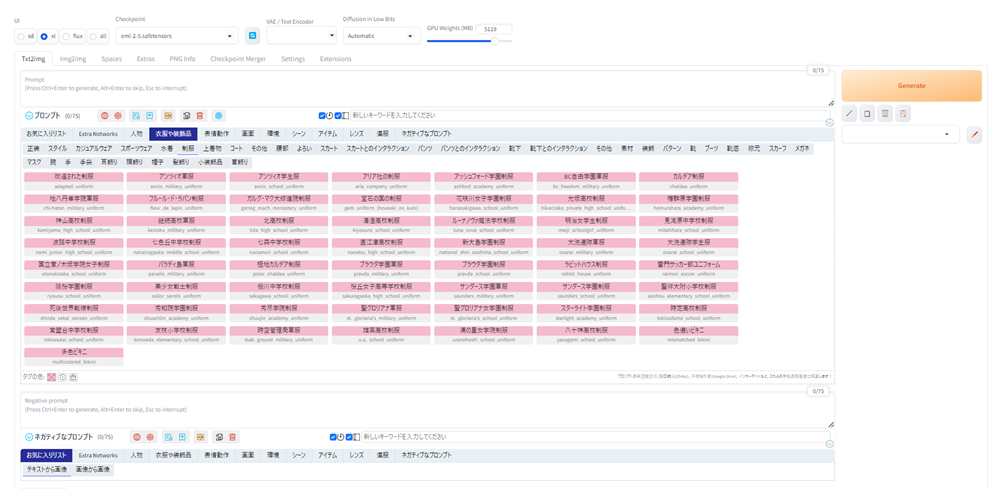
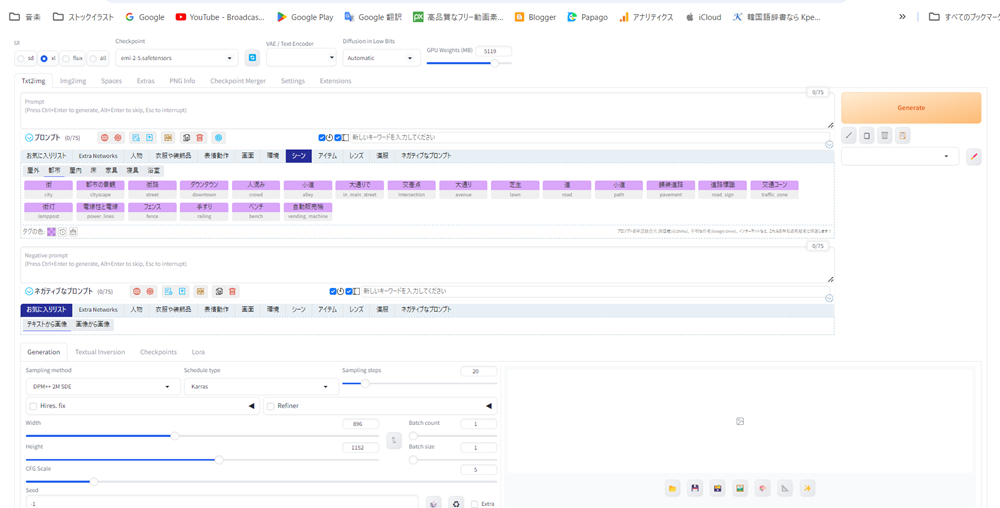
その候補をクリックすると、プロンプト欄に、プロンプトが入力されます。
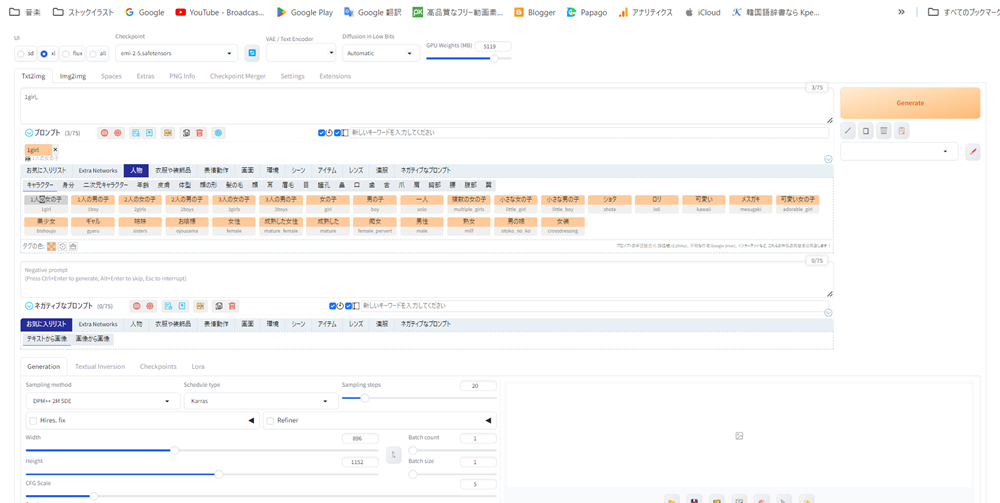
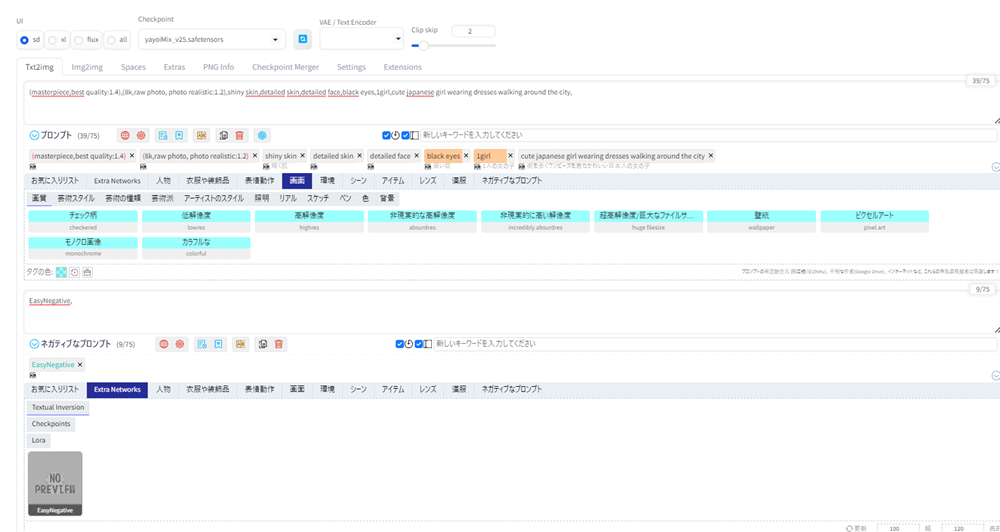
この機能を使って、yayoi_mixをモデルに画像生成した例です。プロンプトに、「1人の女の子」、「微笑」、「水上公園」、「パーカー」、「高解像度」を選びました。
クオリティの高い画像を生成するために、以下の基本となるプロンプトを、prompt-all-in-oneで作ったプロンプトの前に入力します。
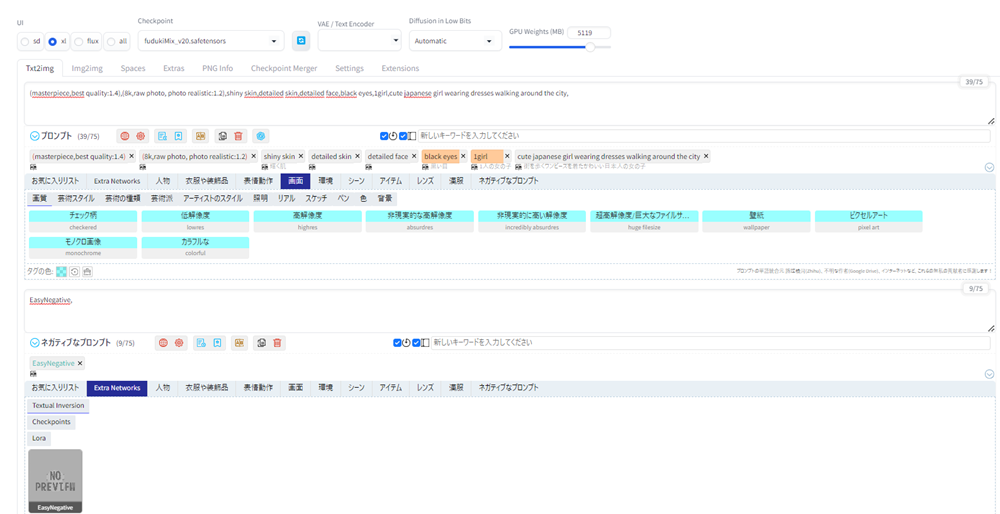
(masterpiece,best quality:1.4),(8k,raw photo, photo realistic:1.2), shiny skin, detailed skin, detailed face, black eyes, 1girl,そして以下のネガティブプロンプトを入力します。
(worst quality,low quality:2),(painting,sketch,flat color),monochrome,grayscale,ugly face,bad face,bad anatomy,deformed eyes,missing fingers,acnes,skin blemishes,nsfw,nude,nipplesそしてGenerateボタンを押します。
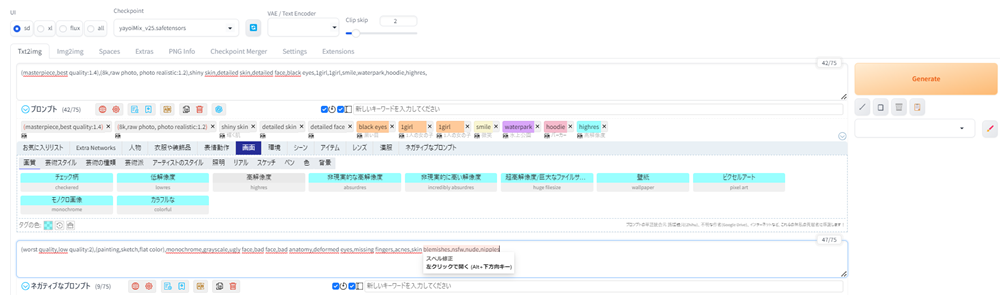
以下が生成した画像です。

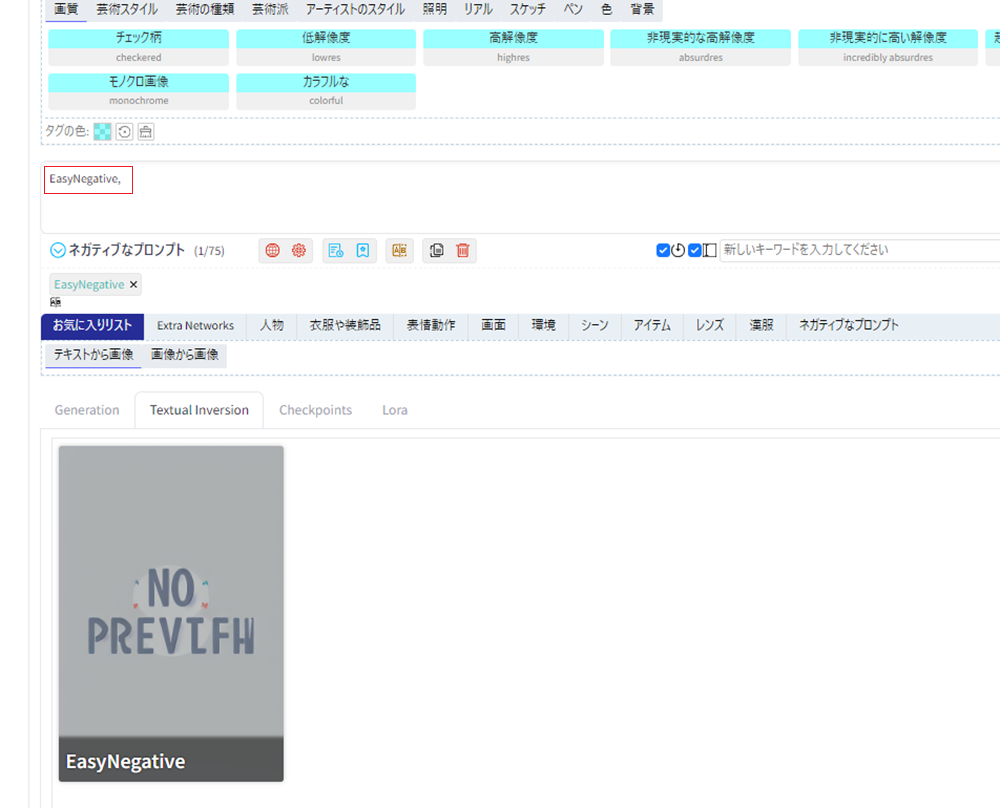
2.EasyNegative
「生成したくない要素」や「避けたい特徴」を指定するためのプロンプトをネガティブプロンプトといいます。
ネガティブプロンプトには、結構の数があり、それを全て入力していては面倒です。
それを解消してくれるのがEasyNegativeです。
EasyNegativeには、多くのネガティブプロンプトが入っていて、これを追加するだけで、ネガティブプロンプトを入力しなくて済みます。
EasyNegativeの追加方法についてご紹介します。
①EasyNegativeのサイトからダウンロードする
以下のサイトに行きます。

EasyNegative.safetensorsの横にあるダウンロードアイコンをクリックし、ダウンロードします。
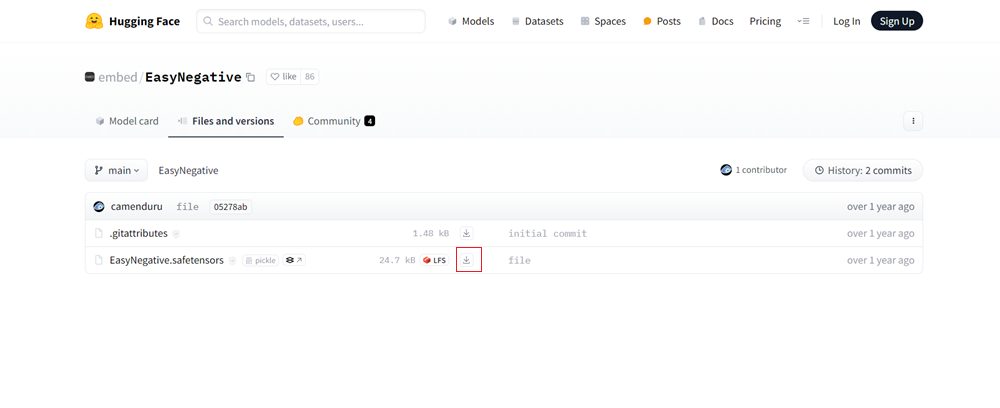
②EasyNegative.safetensorsを「emdenddings」に移す
ダウンロードしたEasyNegative.safetensorsを「emdenddings」に移します。
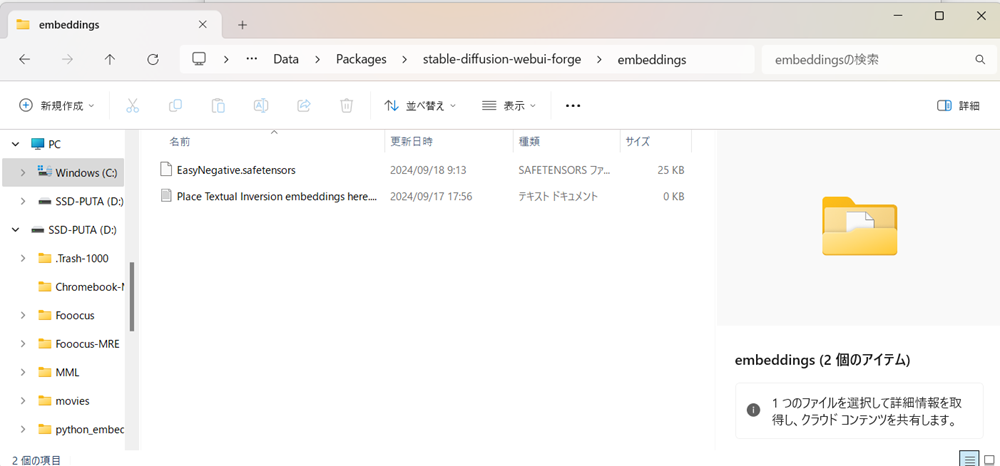
そうしたら、一旦、Stable Diffusion WebUI Forgeを終了し、また起動します。
③EasyNegativeをネガティブプロンプトに設定する
ネガティブプロンプトの入力欄にカーソルを置きます。
Generationの横にあるTextual Inversionタブをクリックします。
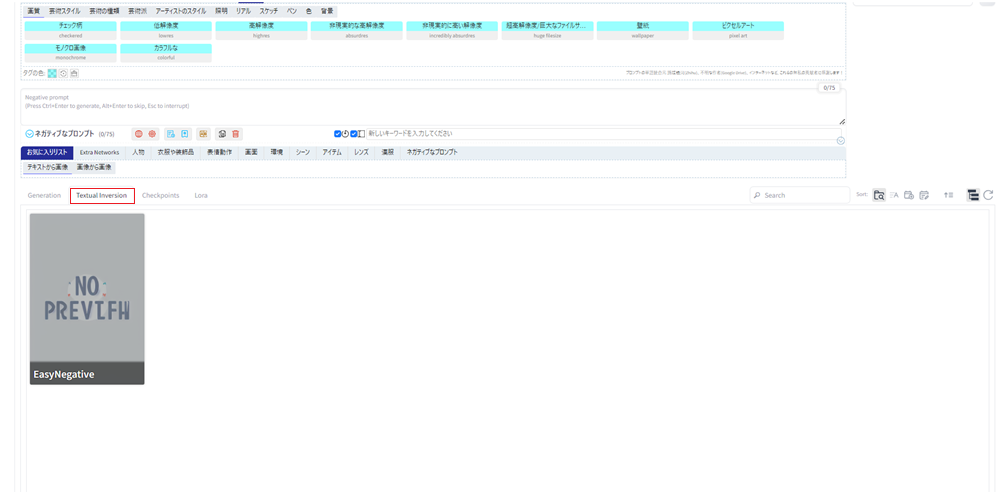
EasyNegativeが入っています。それをクリックします。
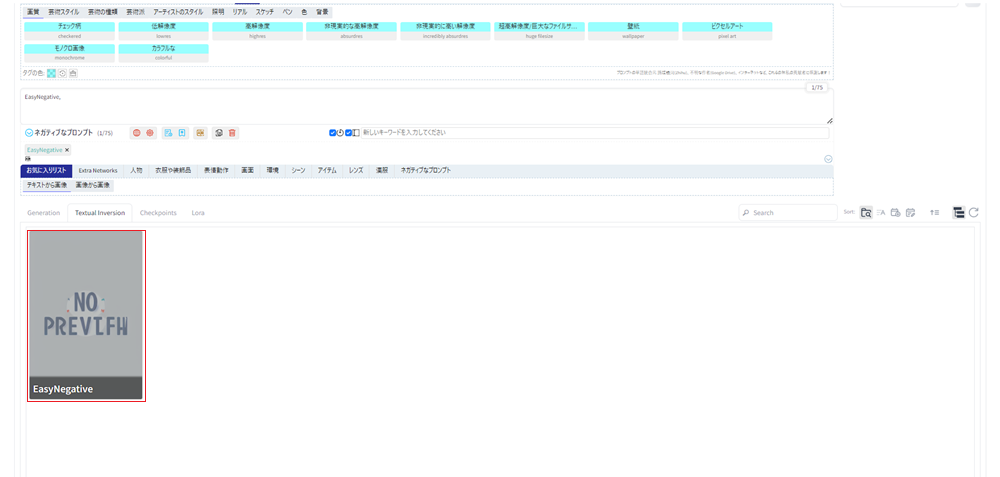
すると、ネガティブプロンプトの入力欄にEasyNegativeと入力されます。
これでEasyNegativeの設定は終了です。
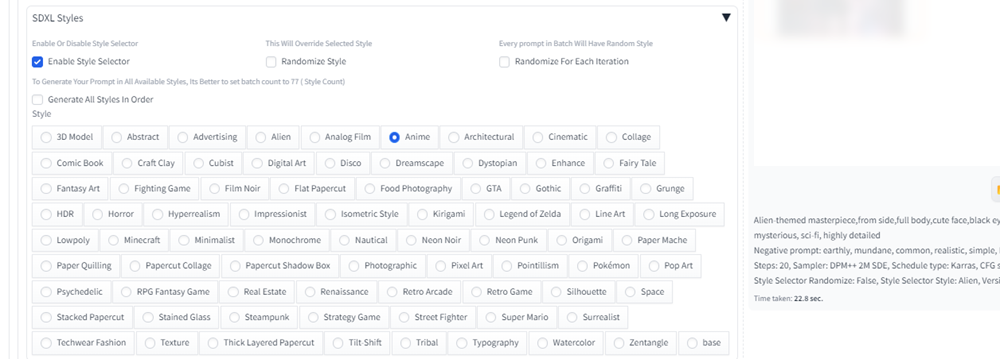
3.Style Selector
画像生成をする際に、例えば実写風、アニメ風、線画風など画像のスタイルを変更する際に、それをわざわざプロンプトで入力するのは面倒です。
そんな時に便利なのがStyle Selectorです。
この拡張機能は、いろんな画像スタイルが用意されていて、それを選択するだけで、画像スタイルを変更できます。
Style Selectorの追加方法についてご紹介します。
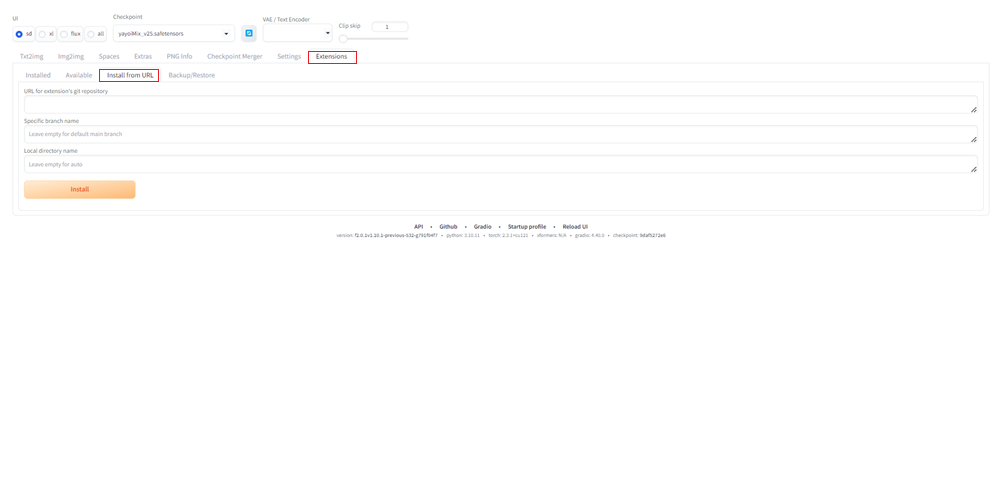
①Extensionsタブを選択し、Install From URLを選択する
Extensionsタブを選択します。
その中にInstall From URLという項目があるので、それを選択します。
②Style SelectorのURLアドレスを入力し、インストールをする
URL for extension’s git repositoryの入力欄に、以下のURLアドレスを入力します。
https://github.com/ahgsql/StyleSelectorXL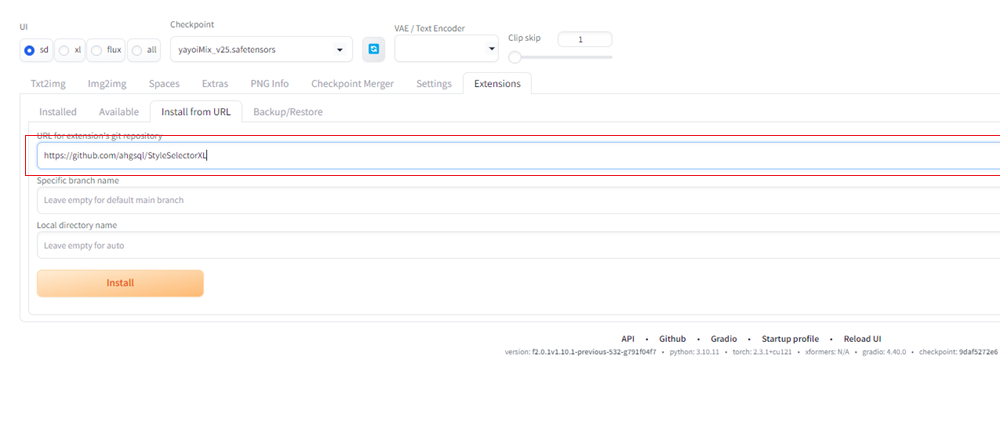
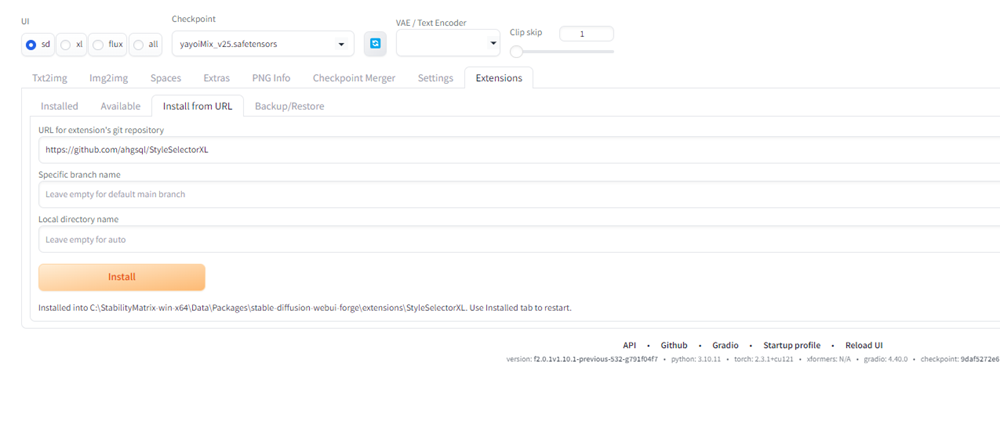
そのあとにInstallボタンをクリックします。
なおこの機能はインストールが完了するまで時間がかかりますが、気長に待ちましょう。
以下の画面のようにInstallボタンの下に文章が現れたらインストール完了です。
③実際にStyle Selectorがインストールされたかを確認し、再起動する
実際にStyle Selectoreがインストールされたかを確認します。
Installedをクリックし、Check for updatesボタンをクリックします。
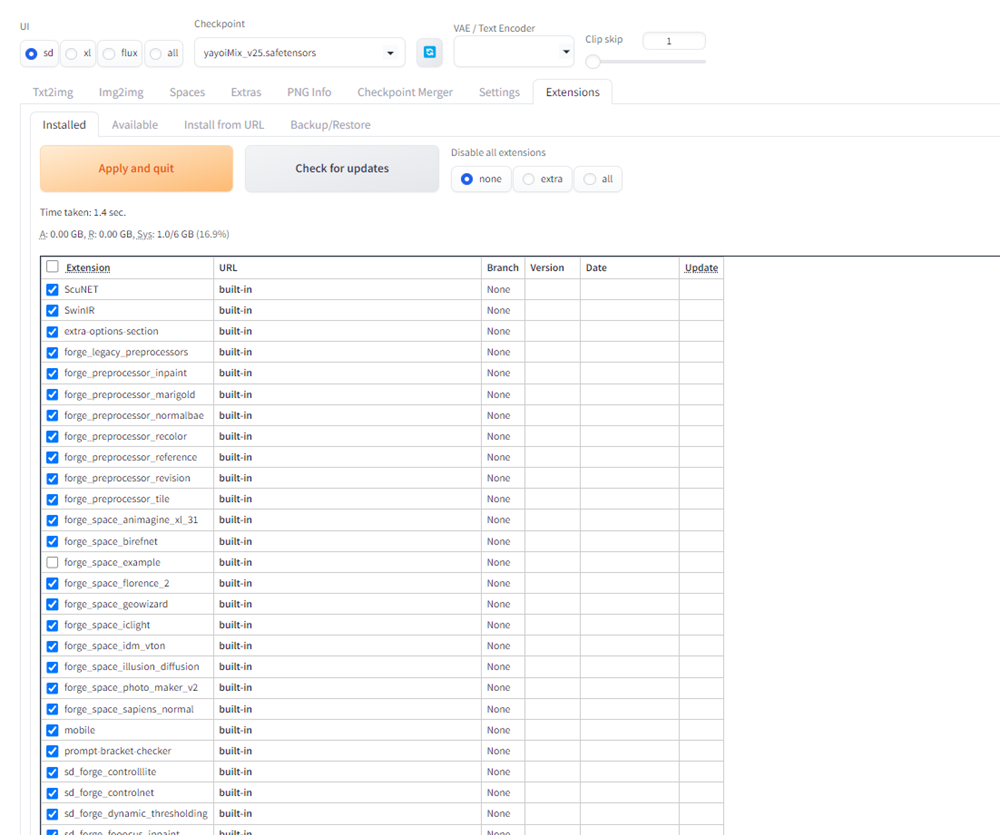
下へスクロールし、以下のような画面
になっていたら、実際にStyle Selectoreがインストールされたことが確認できます。
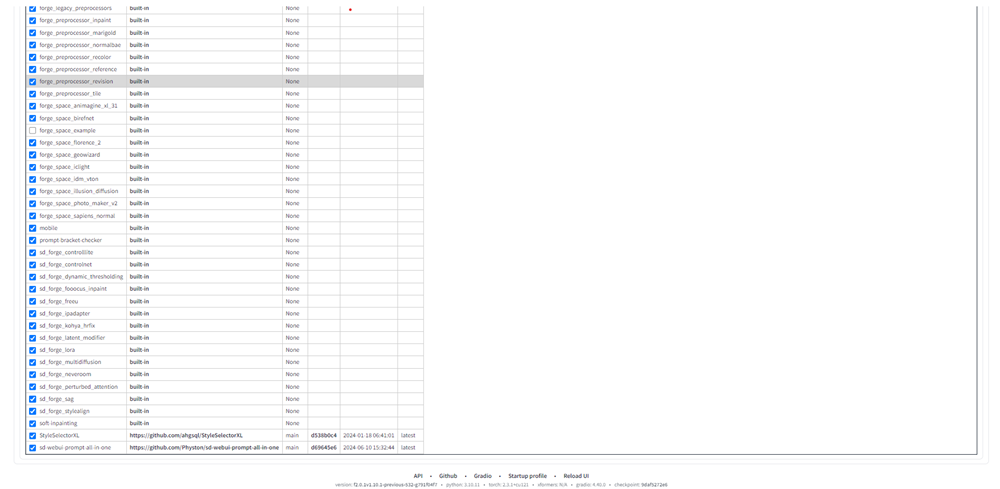
そうしたらAppy and quitボタンをクリックします。
すると、Stable Diffusion WebUI Forgeが再起動します。
なおなかなか再起動しない場合は、手動でStable Diffusion WebUI Forgeを終了させて再起動させてください。
これでStable Diffusion WebUI ForgeにStyle Selectorが追加されました。
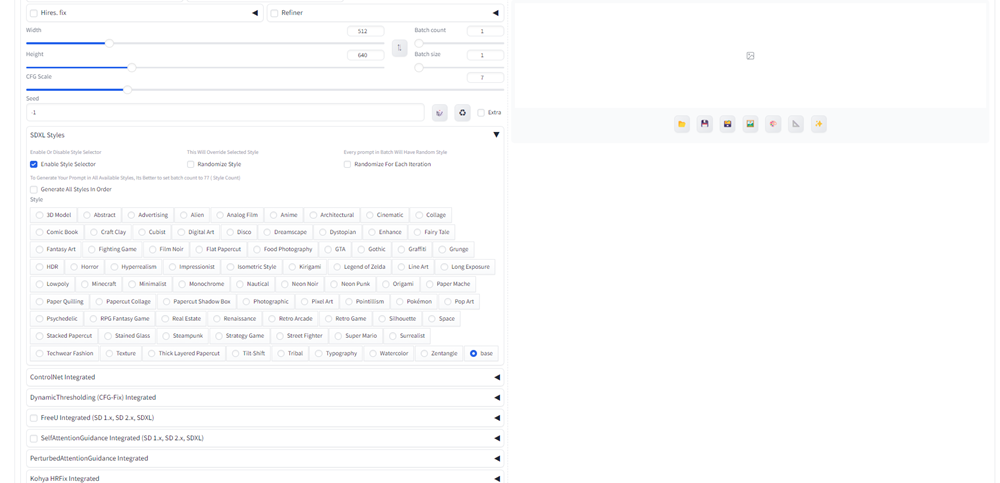
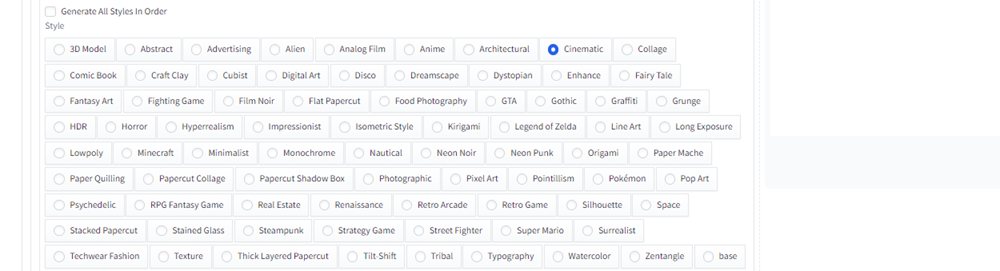
実際にEmi 2.5 Model Cardをモデルに、「街を歩くワンピーズを着たかわいい日本人の女の子」というプロンプトを追加し、Style Selectoreでanimeにチェックを入れて、画像生成してみます。
なおクオリティの高い画像を生成するために、以下の基本となるプロンプトを、prompt-all-in-oneで作ったプロンプトの前に入力します。
masterpiece, from side, full body, cute face, black eyes,1girl,Generationの横にあるTextual Inversionタブをクリックします。
EasyNegativeが入っているので、それをクリックします。
そうすると、ネガティブプロンプトの入力欄にEasyNegativeと入力されます。
その後に、Generateボタンを押します。
生成した画像です。アニメ風の画像が生成されます。

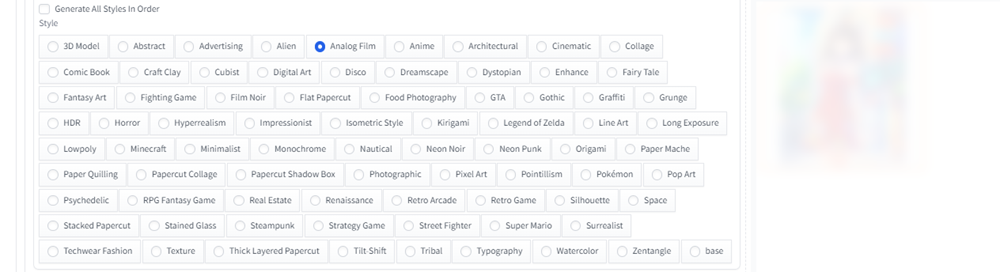
yayoi_mixに「街を歩くワンピーズを着たかわいい日本人の女の子」というプロンプトを追加し、Style SelectoreでAnalog Filmにチェックを入れて、画像生成してみます。
なおクオリティの高い画像を生成するために、以下の基本となるプロンプトを、prompt-all-in-oneで作ったプロンプトの前に入力します。
(masterpiece,best quality:1.4),(8k,raw photo, photo realistic:1.2), shiny skin, detailed skin, detailed face, black eyes, 1girl,そして以下のネガティブプロンプトを入力します。
Generationの横にあるTextual Inversionタブをクリックします。
EasyNegativeが入っているので、それをクリックします。
そうすると、ネガティブプロンプトの入力欄にEasyNegativeと入力されます。
その後に、Generateボタンを押します。
生成した画像です。アナログフィルムで撮ったような画像が生成されます。

fuduki_mixをモデルに、「街を歩くワンピーズを着たかわいい日本人の女の子」というプロンプトを追加し、Style SelectoreでCinematicにチェックを入れて、画像生成してみます。
なおクオリティの高い画像を生成するために、以下の基本となるプロンプトを、prompt-all-in-oneで作ったプロンプトの前に入力します。
(masterpiece,best quality:1.4),(8k,raw photo, photo realistic:1.2), shiny skin, detailed skin, detailed face, black eyes, 1girl,そして以下のネガティブプロンプトを入力します。
Generationの横にあるTextual Inversionタブをクリックします。
EasyNegativeが入っているので、それをクリックします。
そうすると、ネガティブプロンプトの入力欄にEasyNegativeと入力されます。
その後に、Generateボタンを押します。
生成した画像です。シネマティックな画像が生成されます。

画像生成AIに関して
画像生成AIに対しては、さまざまな否定的な声を聞きます。
絵を仕事にしている人の中には「自分の仕事を奪われるのではないか」という不安から敵視する声があります。多くの画像生成AIが既存の絵を無断で学習していることに対して「著作権の問題はどうなっているのか?」と疑問の声もあります。 絵を学んでいる人の中には「自分が積み重ねてきた努力が否定されている気がする」と感じる人もおり、そのような理由から否定的な意見を持つ人もいます。
しかし、私は、ただ否定するのではなく、実際に使ってみた上で意見を持つことが重要ではないかと思います。
現在、テック企業は生成AIを広めることで利益拡大を図っており、赤字を抱えながらも積極的に投資を続けて、いろんなサービスを提供しています。このような状況なので、今後、パソコンを使うユーザーは、画像生成AIを含めた生成AIを活用する機会が自然と多くなると思います。
私自身、絵を描く人間として興味津々で、実際に画像生成AIを使ってみました。
その結果、画像生成AIは自分では思いつかないような構図などを生成してくれるため、アイデア出しのツールとして活用できるなと思いました。
画像生成AIを含めた生成AIはあくまで作業をサポートするためのツールであり、別に完璧な答えを出すものではないと思います。パソコンである以上、どんなに技術が進んでも間違いを出します。優秀なプログラマーが作ったプログラムでもバグが発生するのと同じです。
実際にAIが生成した絵を見て、「この構図なら自分ならこう描く」と思うことが多く、そのまま使う気にはなれませんでした。著作権侵害のリスクを考えると、訴えられる可能性もゼロではないから、テック企業の利益追求のためのツールのために訴えられるのはたまったもんじゃない、とも思います。
ただし、私は画像生成AIを活用して絵を作品として扱う人を否定するつもりはありません。AIで生成された画像は誰でも同じように作れるため、個性が出にくいから、たとえ下手でも生成された絵を参考にして自分なりに描く方がいいのではと思いますすが、これはあくまで絵を描ける人間としての意見であり、他人に押し付けることではありません。
画像生成AIが生成した絵を自分の作品として扱う人は、画像生成AIを使ってみて、自分で導いた答えなので、それを否定する気にはなれません。
私は絵のアイデアツールとして画像生成AIを使っているので、別にイメージ通りの絵が生成する気もないのですが、画像生成AIを使う人の中には、イメージを完璧に再現するためにプロンプトを工夫する人もいます。試しに同じことを自分で行って感じたのは、それが非常に難しいということで、プロンプトを工夫してイメージ通りの絵を生成できる人は、素直にすごいと思います。
ただし、著作権の問題は常につきまといます。AIで生成した画像を自分の作品として扱う場合、著作権侵害で訴えられた場合は、自分で責任を負うべきです。
ただ仕事の資料などで使う画像となると、自分だけの責任だけで著作権の問題は済む話ではありません。
私は、仕事の資料などで使う場合、著作権侵害を考え、生成された画像をそのまま使用するのではなく、Googleの「画像で検索」機能などを活用して類似画像を調べるのがいいかな、と思います。検索窓にフリー素材と入力すると、その中には生成された画像に似たフリー素材として自由に使える画像が出てくるので、それを利用する方が著作権侵害を避けられます。
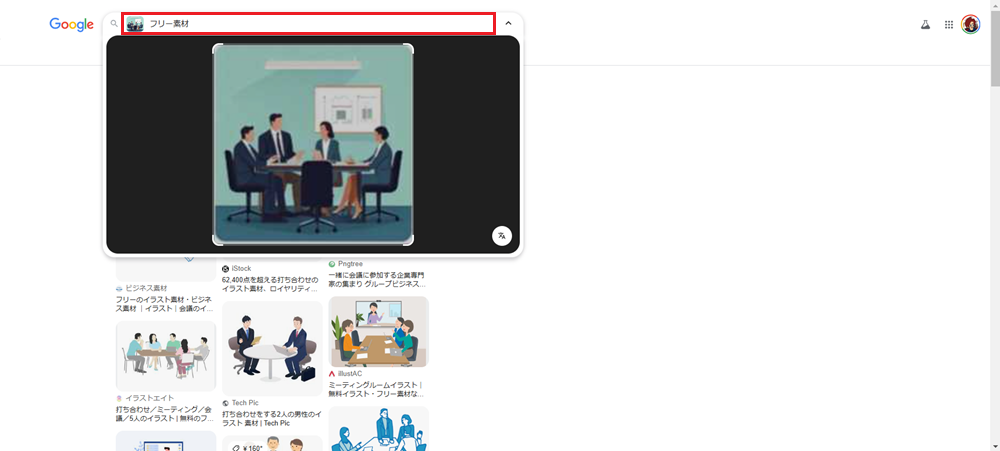
▲Googleの画像検索で、生成した画像を読み込み、検索窓にフリー素材と入力すると、生成された画像に似たフリー素材として自由に使える画像が出てくるのでそれを使うと、著作権侵害は避けられます。
たとえ生成AIで作った画像生成AIを否定する答えを出した人でも、実際に使ってみて、そこから得られるものは多くあると思います。例えば、仕事で生成AIを活用する際、作業効率を上げるためのプロンプトの書き方が重要になりますが、その書き方を画像生成AIを通じて学ぶこともできると思います。
ただ一方で、子どもがAIを使用する場合は注意が必要だと思っています。子どもは無知なので、著作権侵害かどうかを判断できないため、画像生成AIを含めた生成AIでビジネスをして利益を上げたいテック企業という大人たちが集まる集団は、何らかの対策を考えた方がいいのでは、とは思います。
私は、画像生成AIを実際に使ってみて、自分なりの意見を持つことが大切だと思います。

